Copier Le Texte D Un Pdf – Copier le texte d’un PDF peut sembler simple, mais il existe des techniques avancées qui permettent d’automatiser ce processus, d’analyser le texte extrait et de le manipuler pour répondre à des besoins spécifiques. Cet article explore les différentes approches pour extraire, analyser, manipuler, stocker et visualiser le texte extrait d’un PDF, offrant un aperçu complet des possibilités offertes par ce procédé.
Extraction du texte brut d’un PDF: Copier Le Texte D Un Pdf
L’extraction du texte brut d’un fichier PDF est un processus qui permet de récupérer le contenu textuel d’un document PDF sans ses éléments de mise en forme et de mise en page. Cela peut être utile dans diverses situations, telles que l’analyse de texte, l’indexation de documents et la conversion en d’autres formats.
Il existe plusieurs techniques courantes pour extraire du texte brut à partir de fichiers PDF :
Bibliothèques et outils
De nombreuses bibliothèques et outils permettent d’automatiser le processus d’extraction de texte brut à partir de fichiers PDF. Voici quelques exemples :
- PyPDF2: une bibliothèque Python pour manipuler des fichiers PDF, y compris l’extraction de texte.
- PDFMiner: une autre bibliothèque Python pour extraire des informations de documents PDF, notamment du texte brut.
- Adobe Acrobat: un logiciel propriétaire d’Adobe qui permet d’extraire du texte brut à partir de fichiers PDF.
Avantages et inconvénients
Chaque approche d’extraction de texte brut présente ses propres avantages et inconvénients :
- Bibliothèques tierces :Elles offrent une flexibilité et un contrôle accrus, mais nécessitent une connaissance de la programmation.
- Outils propriétaires :Ils sont généralement plus faciles à utiliser, mais peuvent être coûteux et limités en termes de fonctionnalités.
Analyse du texte extrait
L’analyse du texte extrait est cruciale pour identifier les informations clés, les entités et les relations présentes dans le document.Le traitement du langage naturel (PNL) joue un rôle essentiel dans l’analyse de texte. Les techniques de PNL permettent d’extraire des informations structurées à partir de textes non structurés.
Ces techniques comprennent :
- Tokenisation : diviser le texte en mots individuels ou jetons.
- Lemmatisation : réduire les mots à leur forme de base (lemme).
- Étiquetage grammatical : identifier les parties du discours de chaque mot.
- Analyse syntaxique : analyser la structure grammaticale du texte.
L’analyse de texte trouve de nombreuses applications dans différents domaines :
- Recherche d’informations : extraire des informations pertinentes à partir de documents volumineux.
- Résumé automatique : générer des résumés concis de textes longs.
- Classification de texte : catégoriser les documents en fonction de leur contenu.
- Extraction de faits : identifier et extraire des faits spécifiques à partir de textes.
- Traduction automatique : traduire des textes d’une langue à une autre.
Manipulation du texte extrait

Une fois le texte extrait d’un PDF, il peut être manipulé pour le formater, le résumer ou le traduire. La manipulation de texte fait référence aux techniques utilisées pour traiter et transformer le texte afin de le rendre plus utile ou adapté à des tâches spécifiques.
Les techniques courantes de manipulation de texte comprennent :
- Tokenisation :Diviser le texte en unités plus petites, appelées jetons. Les jetons peuvent être des mots, des phrases ou d’autres unités de signification.
- Lemmatisation :Réduire les mots à leur forme racine, ou lemme. Cela permet de normaliser le texte et d’améliorer la précision des tâches de traitement du langage naturel.
- Suppression des mots vides :Supprimer les mots courants qui n’ajoutent pas beaucoup de signification au texte, tels que les articles, les prépositions et les conjonctions.
La manipulation de texte trouve de nombreuses applications pratiques, notamment :
- Résumé de texte :Générer des résumés concis et informatifs à partir de textes longs.
- Traduction :Convertir du texte d’une langue à une autre.
- Analyse des sentiments :Déterminer le sentiment ou l’émotion exprimée dans un texte.
Stockage et gestion du texte extrait

Le stockage et la gestion du texte extrait sont essentiels pour garantir son organisation, sa sécurité et sa récupération efficace. Voici les options de stockage courantes :
- Bases de données :Les bases de données relationnelles ou non relationnelles peuvent stocker de grandes quantités de texte extrait, permettant une recherche et une récupération efficaces.
- Fichiers texte :Les fichiers texte sont simples et faciles à utiliser, mais ils peuvent être volumineux et difficiles à organiser pour les grandes quantités de texte.
- Systèmes de gestion de contenu (CMS) :Les CMS sont conçus pour gérer et organiser le contenu, y compris le texte extrait, offrant des fonctionnalités telles que la recherche, l’édition et la collaboration.
Les stratégies de gestion du texte peuvent inclure :
- Organisation :Structurer le texte extrait en catégories, balises ou métadonnées pour faciliter la récupération.
- Sécurité :Mettre en œuvre des mesures de sécurité pour protéger le texte extrait contre les accès non autorisés.
- Sauvegarde :Créer des sauvegardes régulières pour éviter la perte de données en cas de panne ou de catastrophe.
- Indexation :Indexer le texte extrait pour permettre une recherche rapide et efficace.
Exemples de systèmes de gestion de texte :
- Elasticsearch :Un moteur de recherche et d’analyse distribué conçu pour gérer de grands volumes de données textuelles.
- MongoDB :Une base de données NoSQL qui peut stocker et gérer des documents textuels.
- Alfresco :Un CMS open source qui fournit des fonctionnalités de gestion de contenu et de documents.
Visualisation et présentation du texte extrait
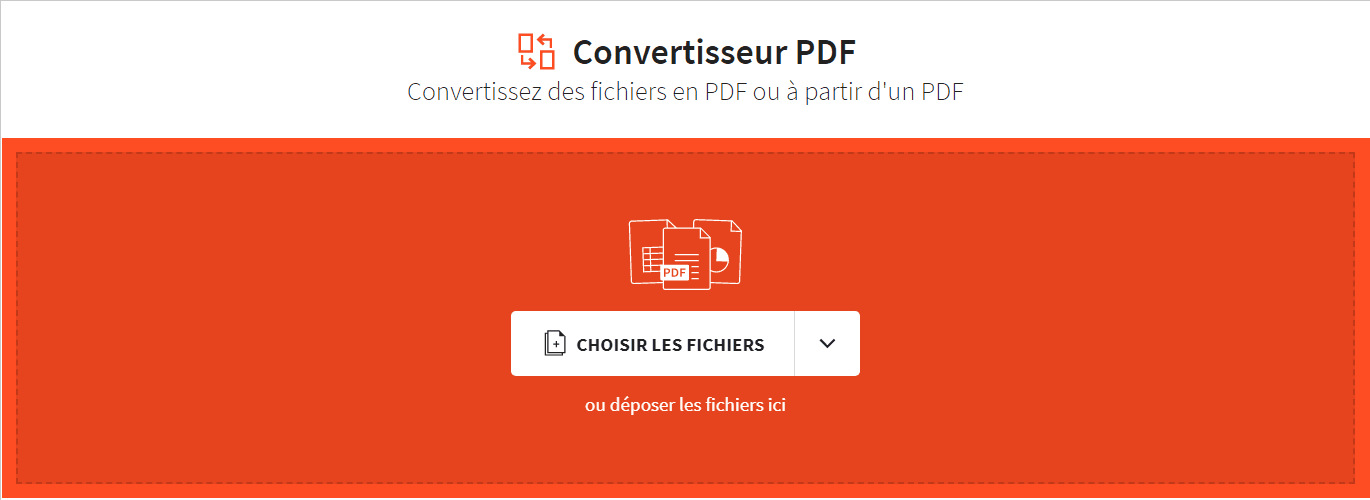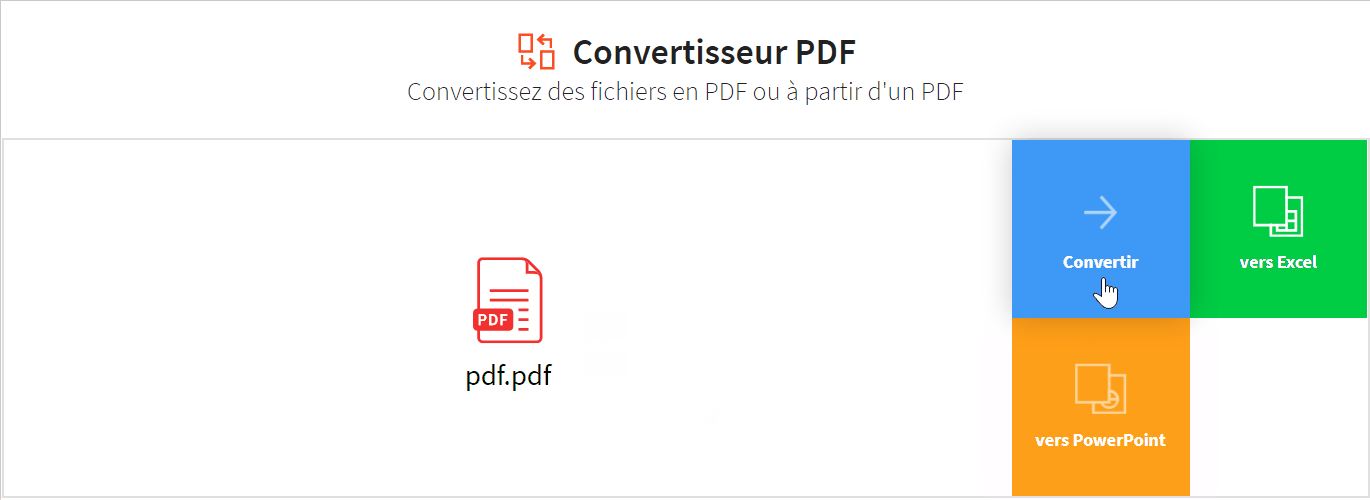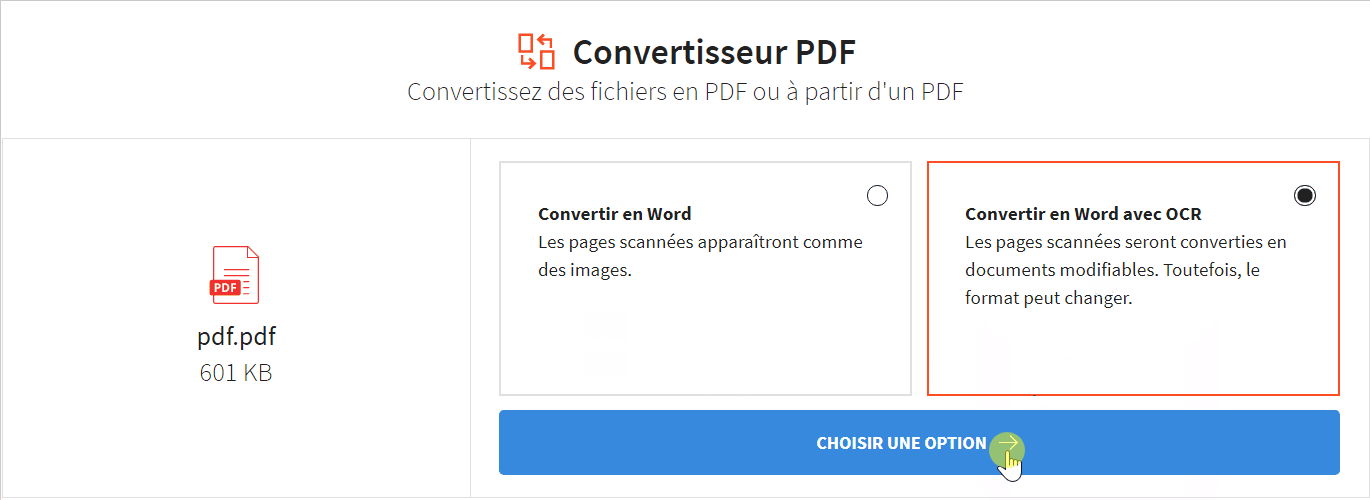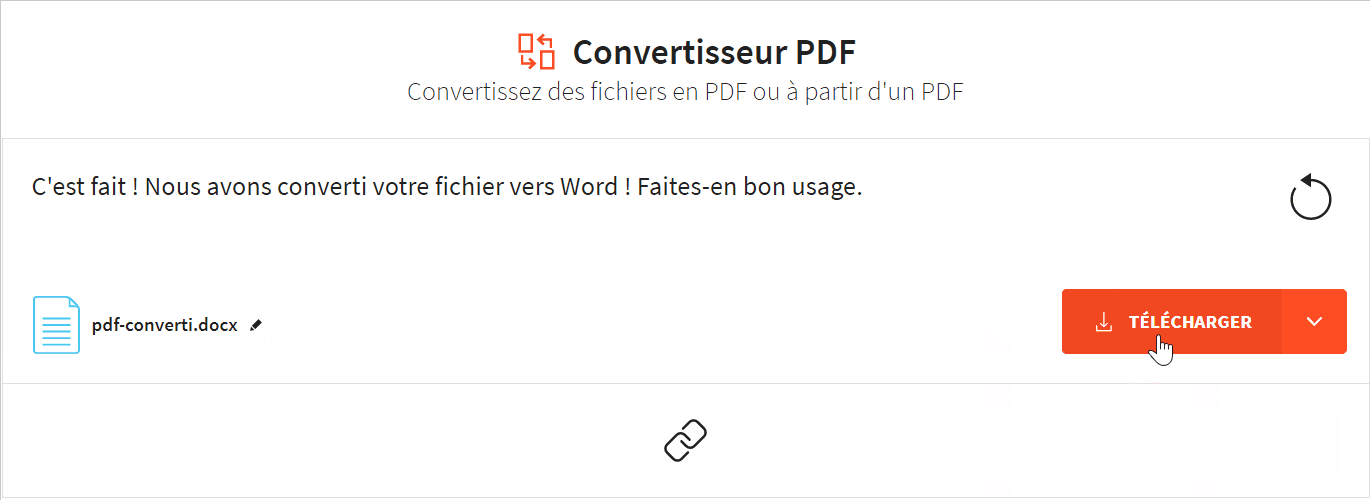
Pour faciliter la compréhension et l’analyse du texte extrait, il est essentiel de le visualiser et de le présenter de manière claire et efficace.
Plusieurs techniques de visualisation de données peuvent être utilisées pour représenter le texte extrait, notamment les graphiques, les tableaux et les nuages de mots.
Graphiques, Copier Le Texte D Un Pdf
Les graphiques sont un moyen puissant de visualiser les tendances et les relations dans les données textuelles. Ils peuvent être utilisés pour représenter la fréquence des mots, les relations entre les mots ou les sentiments exprimés dans le texte.
- Les histogrammes peuvent montrer la distribution de la fréquence des mots ou des phrases.
- Les diagrammes circulaires peuvent représenter la proportion de différentes catégories de mots ou de sentiments.
- Les graphiques en courbes peuvent montrer l’évolution de la fréquence des mots ou des sentiments dans le temps.
Tableaux
Les tableaux peuvent être utilisés pour organiser et présenter des données textuelles de manière structurée. Ils peuvent être utilisés pour afficher des informations telles que la fréquence des mots, les relations entre les mots ou les sentiments exprimés dans le texte.
Les tableaux peuvent être triés et filtrés pour faciliter l’identification des tendances et des modèles dans les données.
Nuages de mots
Les nuages de mots sont une représentation visuelle de la fréquence des mots dans un texte. Les mots les plus fréquents sont représentés par des caractères plus grands et plus gras, tandis que les mots moins fréquents sont représentés par des caractères plus petits et plus fins.
Les nuages de mots peuvent fournir un aperçu rapide des sujets et des thèmes principaux abordés dans un texte.
En maîtrisant les techniques décrites dans cet article, vous pourrez débloquer la valeur cachée des documents PDF, extraire des informations précieuses et les exploiter pour améliorer vos processus métier et vos applications.


